깃허브에서 가져온 기존 모델을 활용하여 최적화하는 과정이다
이 코드 전에 수집 데이터는 내가 원하는 제스처 데이터가 없어서 수작업으로 제스처 데이터를 모았다.
기존코드
import numpy as np
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'
actions = [
'Lv1', 'Lv2', 'Lv3'
]
data = np.concatenate([
np.load('dataset/seq_Lv1_1742691808.npy'),
np.load('dataset/seq_Lv2_1742691808.npy'),
np.load('dataset/seq_Lv3_1742691808.npy')
], axis=0)
data.shape
x_data = data[:, :, :-1]
labels = data[:, 0, -1]
print(x_data.shape)
print(labels.shape)
from tensorflow.keras.utils import to_categorical
y_data = to_categorical(labels, num_classes=len(actions))
y_data.shape
from sklearn.model_selection import train_test_split
x_data = x_data.astype(np.float32)
y_data = y_data.astype(np.float32)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.1, random_state=2021)
print(x_train.shape, y_train.shape)
print(x_val.shape, y_val.shape)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(64, activation='relu', input_shape=x_train.shape[1:3]),
Dense(32, activation='relu'),
Dense(len(actions), activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
model.summary()
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=200,
callbacks=[
ModelCheckpoint('models/model.h5', monitor='val_acc', verbose=1, save_best_only=True, mode='auto'),
ReduceLROnPlateau(monitor='val_acc', factor=0.5, patience=50, verbose=1, mode='auto')
]
)
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots(figsize=(16, 10))
acc_ax = loss_ax.twinx()
loss_ax.plot(history.history['loss'], 'y', label='train loss')
loss_ax.plot(history.history['val_loss'], 'r', label='val loss')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
loss_ax.legend(loc='upper left')
acc_ax.plot(history.history['acc'], 'b', label='train acc')
acc_ax.plot(history.history['val_acc'], 'g', label='val acc')
acc_ax.set_ylabel('accuracy')
acc_ax.legend(loc='upper left')
plt.show()
from sklearn.metrics import multilabel_confusion_matrix
from tensorflow.keras.models import load_model
model = load_model('models/model.h5')
y_pred = model.predict(x_val)
multilabel_confusion_matrix(np.argmax(y_val, axis=1), np.argmax(y_pred, axis=1))코드 변경
import numpy as np
import os
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from sklearn.metrics import multilabel_confusion_matrix
import matplotlib.pyplot as plt
from tensorflow.keras.models import load_model
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'
actions = ['Lv1', 'Lv2', 'Lv3']
data = np.concatenate([
np.load('dataset/seq_Lv1_1742691808.npy'),
np.load('dataset/seq_Lv2_1742691808.npy'),
np.load('dataset/seq_Lv3_1742691808.npy')
], axis=0)
print(f"Data shape: {data.shape}")
x_data = data[:, :, :-1]
labels = data[:, 0, -1]
y_data = to_categorical(labels, num_classes=len(actions))
x_data = x_data.astype(np.float32)
y_data = y_data.astype(np.float32)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.1, random_state=2021)
#모델 구조 정의
model = Sequential([
LSTM(128, activation='tanh', input_shape=x_train.shape[1:3], return_sequences=True),
Dropout(0.2), #Dropout 추가/ 과적합 방지
LSTM(64, activation='tanh'), #LSTM 층 2개 추가
Dropout(0.2), #Dropout 추가
Dense(32, activation='relu'),
Dense(len(actions), activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
model.summary()
callbacks = [
ModelCheckpoint('models/model.h5', monitor='val_acc', verbose=1, save_best_only=True, mode='auto'),
ReduceLROnPlateau(monitor='val_acc', factor=0.5, patience=50, verbose=1, mode='auto'),
EarlyStopping(monitor='val_loss', patience=30, verbose=1, mode='auto') # EarlyStopping 추가
]
#모델 학습
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=200,
batch_size=64, #배치 사이즈 추가
callbacks=callbacks
)
#훈련 과정 시각화
fig, loss_ax = plt.subplots(figsize=(16, 10))
acc_ax = loss_ax.twinx()
loss_ax.plot(history.history['loss'], 'y', label='train loss')
loss_ax.plot(history.history['val_loss'], 'r', label='val loss')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
loss_ax.legend(loc='upper left')
acc_ax.plot(history.history['acc'], 'b', label='train acc')
acc_ax.plot(history.history['val_acc'], 'g', label='val acc')
acc_ax.set_ylabel('accuracy')
acc_ax.legend(loc='upper left')
plt.show()
model = load_model('models/model.h5')
y_pred = model.predict(x_val)
mcm = multilabel_confusion_matrix(np.argmax(y_val, axis=1), np.argmax(y_pred, axis=1))
print(mcm)개선 방향
1. LSTM 층 활성화 함수 변경 (tanh vs relu)
LSTM 네트워크에서 relu 활성화 함수는 보통 잘 동작하지 않는다.
순환 신경망(RNN)에서는 장기적인 의존성을 처리하는 데 어려움이 있을 수 있다
기존 activation='relu'
변경 activation='tanh'
2. LSTM 층 추가 및 Dropout 사용
원래의 모델은 LSTM 층을 하나만 사용하고 있었기 때문에 복잡한 시계열 데이터를 처리하는 데 한계가 있었을 수 있고 과적합이 발생할 가능성이 있다. 과적합은 모델이 훈련 데이터에 너무 맞춰져서 조금만 값이 바뀌어도 맞추지 못하는 등 실제 데이터에서 성능이 떨어지는 문제를 일으킨다
LSTM(128, activation='tanh', input_shape=x_train.shape[1:3], return_sequences=True),
Dropout(0.2), #Dropout을 추가해서 과적합 방지Dropout : 임의로 일부 뉴런을 비활성화하여 네트워크가 특정 입력에 과도하게 의존하지 않도록 도움(과적합 방지)
3. 조기 종료(EarlyStopping) 추가
모델이 더 이상 성능이 향상되지 않거나 검증에서 오차가 증가하기 시작할때 불필요하게 학습을 더 진행할 수 있는데 이럴 때는 학습을 멈추는 것이 효율적이다
EarlyStopping콜백을 추가하여 val_loss이 일정 epoch 동안 개선되지 않으면 학습을 중단하도록 했다. 이렇게 하면 학습 시간도 단축되고, 과적합도 방지할 수 있다
EarlyStopping(monitor='val_loss', patience=30, verbose=1, mode='auto')
#EarlyStopping 추가
4. 모델 체크포인트 및 학습률 조정
훈련 중에 성능이 좋아지지 않거나 학습률이 너무 커서 최적의 값을 찾기 어려운 경우가 발생할 수 있는데 이럴 때는 모델을 최적화하기 위해 학습률을 자동으로 조정하거나 최상의 상태에서 모델을 저장하는 것이 필요하다
val_acc가 개선될 때마다 가장 좋은 모델을 저장하게 하면 학습이 끝나고 난 후에 가장 좋은 상태의 모델을 쉽게 불러올 수있다.
ModelCheckpoint('models/model.h5', monitor='val_acc', verbose=1,
save_best_only=True, mode='auto'),
5. 배치 크기(batch_size) 조정
배치 크기가 너무 작거나 크면, 훈련 속도나 성능에 문제가 생길 수 있어서 batch_size를 64로 설정하여 적당한 크기로 훈련을 진행했다. 대체로 모델 성능과 훈련 속도 간의 균형을 잘 맞출 수 있는 값이다.
#모델 학습 코드
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=200,
batch_size=64, #배치 사이즈 64로 추가
callbacks=callbacks
)기존의 코드와 변경 후 코드의 훈련과정을 비교
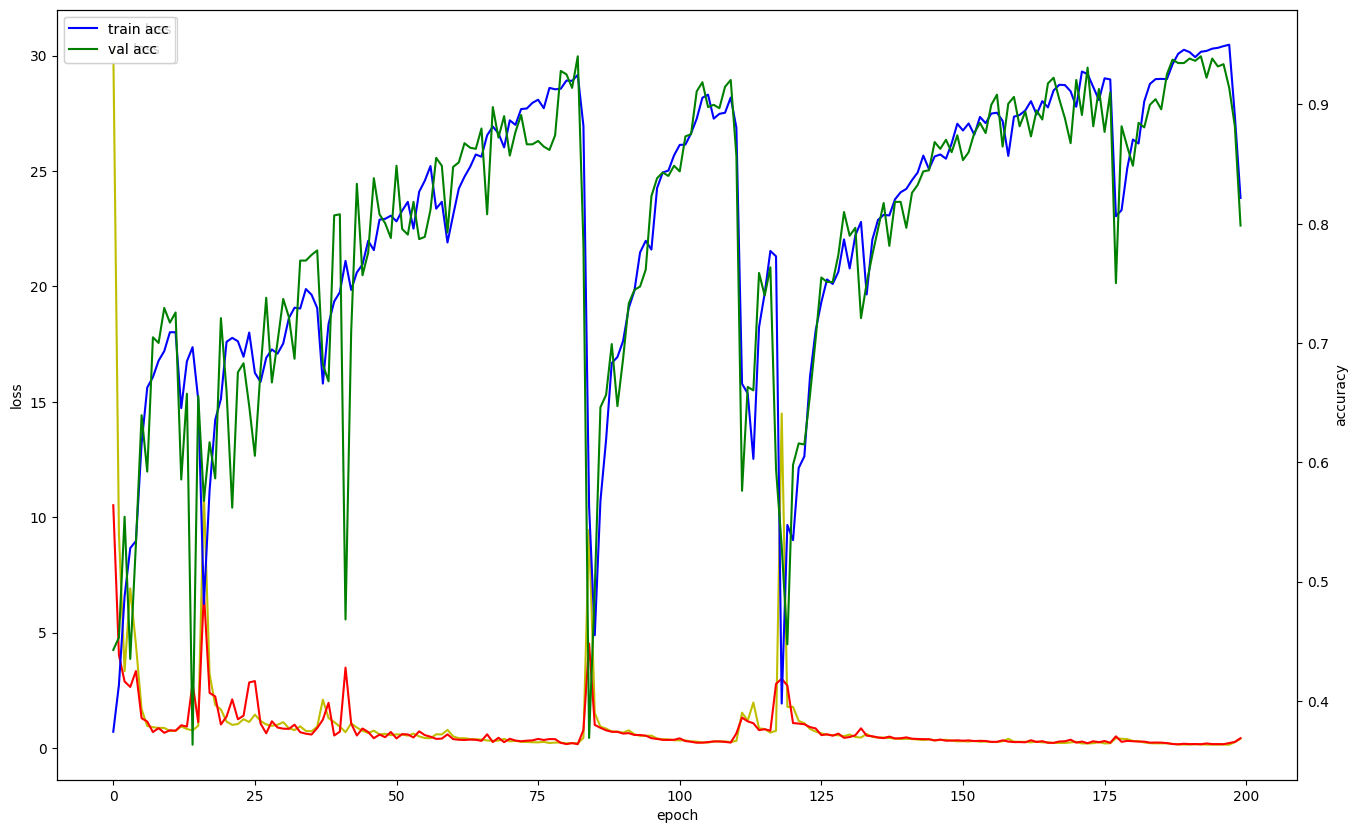
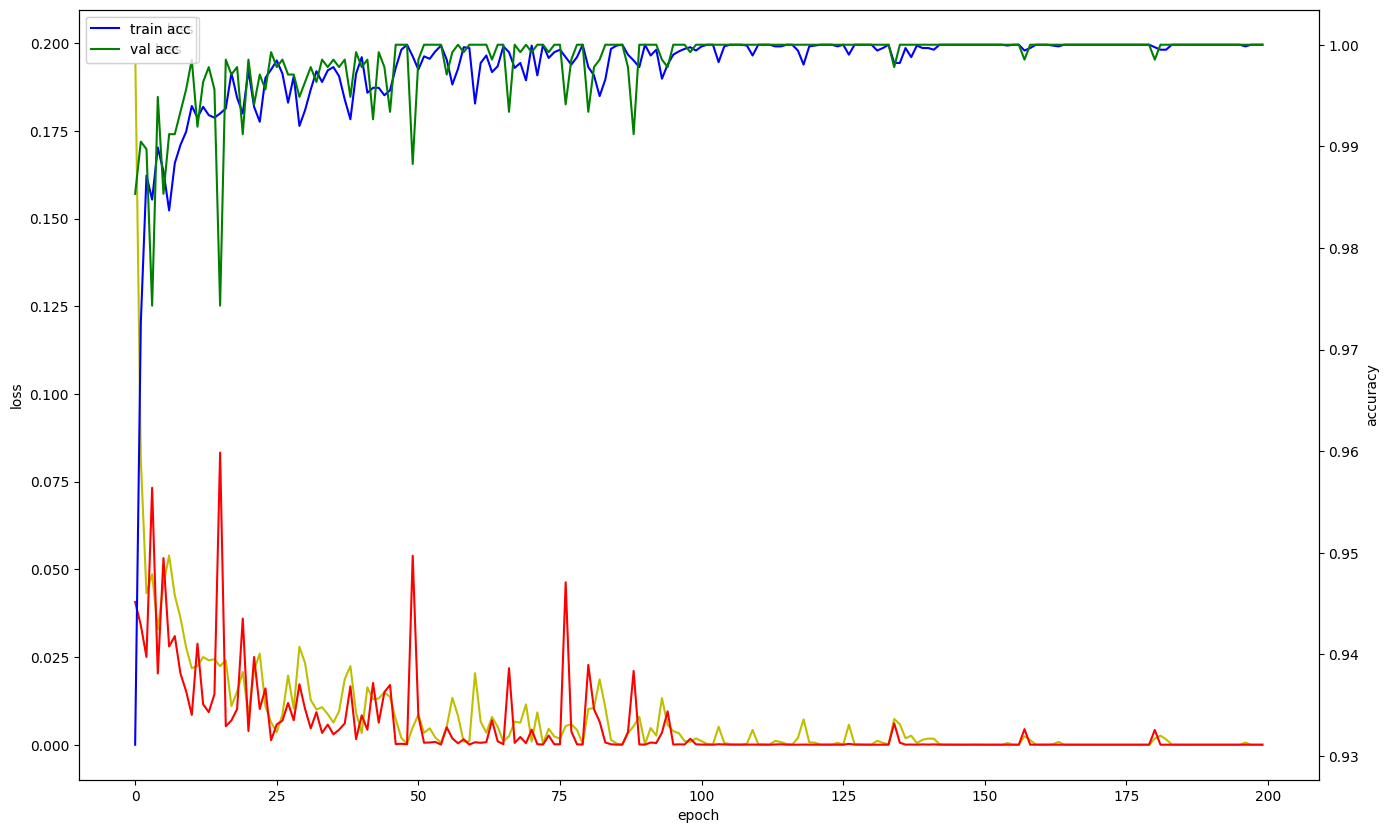
'인공지능 > 인공지능' 카테고리의 다른 글
| LSTM기반 제스처 구조 요청 시스템 - 서버 관점 (3) | 2025.06.11 |
|---|---|
| LSTM (0) | 2025.03.22 |
| 배열과 행렬의 원소 선택하기 (1) | 2024.08.19 |
| 희소 행렬(Sparse Matrix) 생성 및 변환 (0) | 2024.08.18 |
| 다양한 행렬 생성 및 초기화 방법 (0) | 2024.08.18 |



