[풀스택 개발 팀 프로젝트]
우리 팀은 프론트엔드, 백엔드, AI(알고리즘) 담당으로 구성된 3인 팀으로, 나는 AI부분을 맡았다
기존 유튜브 알고리즘의 한계를 개선하고, 우리만의 방식으로 사용자 맞춤형 추천 시스템을 구현했다.
이 글에서는 카테고리 분류 부분만 진행하고 추후 추천 부분도 작성할 예정
프로젝트 추진배경
- 숏폼 콘텐츠(유튜브 쇼츠, 틱톡, 인스타 릴스)의 급성장으로 개인 관심사에 맞는 추천 시스템의 중요성이 증가
- 기존의 유튜브는 알고리즘은 사용자 개인의 선호를 완벽히 반영하지 못하거나, 관련성 낮은 콘텐츠가 제공되는 문제 발생
활용목적 및 타겟
- 관심사에 맞는 맞춤형 숏폼 콘텐츠 제공
- 콘텐츠 소비 시간 절약 및 만족도 향상
- 더 나은 몰입 경험으로 플랫폼 사용 증가 기대
- 짧은 시간 내 효율적인 콘텐츠 탐색을 원하는 사람들
역할
- 알고리즘 설계 및 구현
- TF-IDF, 코사인 유사도, KNN 알고리즘을 활용해 개인화된 추천 시스템 개발
- 유튜브 데이터 API를 통해 수집한 콘텐츠 메타데이터(제목, 해시태그 등)를 기반으로 영상 간 연관성 계산
- 데이터 기반 추천 시스템 개발
- 영상 제목과 해시태그에서 키워드를 추출하고 이를 기반으로 연관성 높은 콘텐츠를 추천
- 추천 시스템의 효율성을 높이기 위해 텍스트 데이터 전처리 및 키워드 분석 자동화
핵심
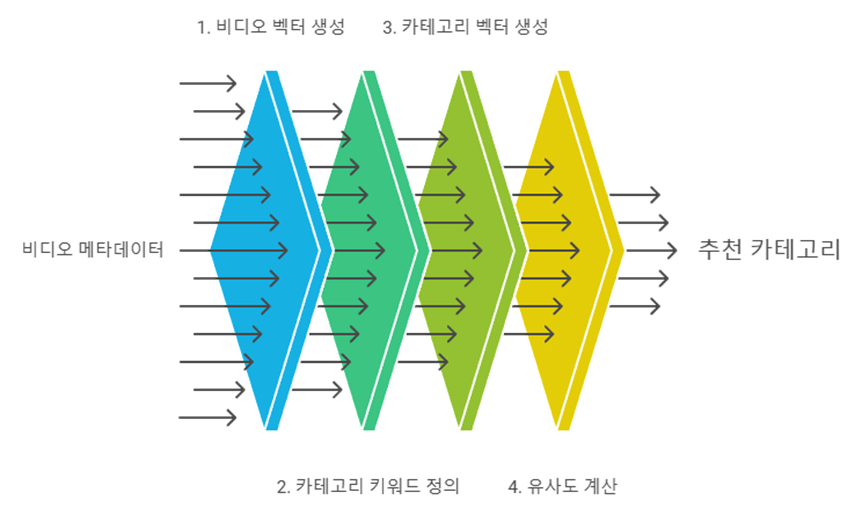
각 영상의 제목, 설명, 해시태그를 결합하여 텍스트로 만들고, 이를 TF-IDF 벡터화하여 벡터 생성
미리 정의해놓은 카테고리 키워드들을 텍스트로 구성하여 벡터화하고, 영상 벡터와 카테고리 벡터들 간의 코사인 유사도를 계산
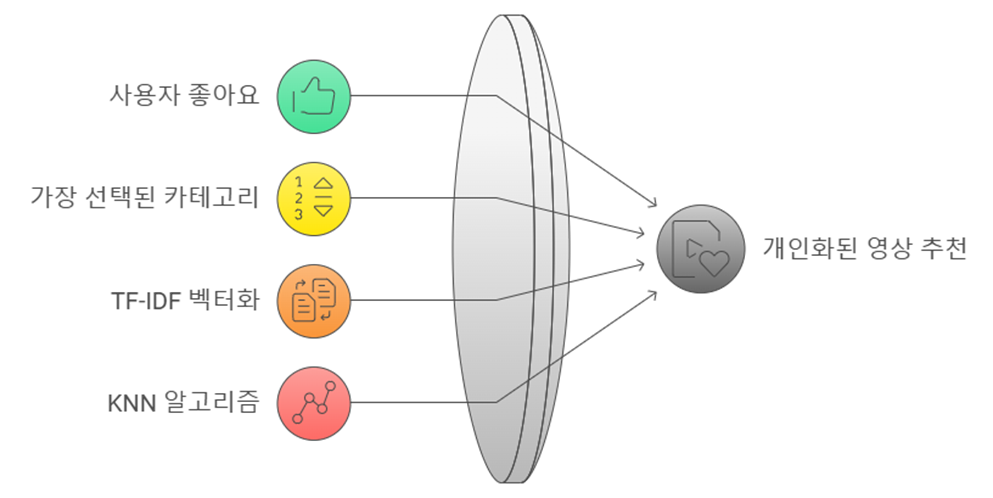
사용자가 좋아요 누른 영상DB에 저장되고 가장 많이 선택된 카테고리를 파악한 후, 해당 카테고리의 영상들의 제목과 설명, 해시태그를 TF-IDF 방식으로 벡터화 후 KNN 알고리즘의 특징으로 활용
START
사용 라이브러리들
import numpy as np
import random
import isodate #ISO 8601 포맷의 날짜 및 시간 파싱
import time
from googleapiclient.discovery import build #유튜브 API 호출
from sklearn.feature_extraction.text import TfidfVectorizer #TF-IDF 벡터화
from sklearn.metrics.pairwise import cosine_similarity #텍스트 유사도 계산 (코사인 유사도)
from pymongo import MongoClient
from datetime import datetime데이터베이스 연결 (MongoDB)
API_KEY = "발급받은 유튜브 API 키"
youtube = build('youtube', 'v3', developerKey=API_KEY)
def connect_mongodb(): #데이터베이스 연결
try:
client = MongoClient('mongodb://localhost:27017/') #DB 연결
db = client['videos']
return db
except Exception as e:
print(f"MongoDB 연결 오류: {str(e)}")
return None유튜브 API 활용하여 무작위 영상 받아오는 함수
#최대 500개의 영상 가져오기
def get_videos(max_results=2500):
videos = []
page_token = None
try:
for _ in range(20): #최대 20번 호출해서 500개까지 요청
#랜덤 좌표 생성 (한국 내)
latitude = random.uniform(33.0, 43.0) #위도
longitude = random.uniform(124.0, 132.0) #경도
location = f"{latitude},{longitude}"
location_radius = "50km" #반경 50km
request_params = {
'part': 'snippet',
'type': 'video',
'maxResults': 50, # 한번 요청에서 최대 50개
'regionCode': 'KR', #한국 지역
'location': location,
'locationRadius': location_radius,
'pageToken': page_token #다음 페이지 토큰
}
request = youtube.search().list(**request_params)
response = request.execute()
#영상정보 추출
for item in response['items']:
video_id = item['id']['videoId']
videos.append({
'title': item['snippet']['title'],
'description': item['snippet']['description'],
'video_id': video_id,
'published_at': item['snippet']['publishedAt']
})
#다음 페이지 토큰
page_token = response.get('nextPageToken')
if not page_token:
break # 더 이상 페이지가 없으면 종료
time.sleep(0.1) #요청 간의 대기 시간
except Exception as e:
print(f"동영상 검색 중 오류 발생: {str(e)}")
return videosAPI로 받아온 랜덤 유튜브 영상 중 1분 이하이고 실시간 방송이 아닌 영상 필터링
def filter_and_categorize_videos(videos):
filtered_videos = []
for video in videos:
#영상 세부 정보 가져오기 (재생 시간 및 실시간 여부)
video_details = youtube.videos().list(
part="contentDetails, liveStreamingDetails",
id=video['video_id']
).execute()
details = video_details['items'][0]
duration = details['contentDetails']['duration'] #영상 길이
is_live = 'liveStreamingDetails' in details #실시간 방송 여부
duration_seconds = isodate.parse_duration(duration).total_seconds() #영상 길이(초)
#실시간이 아니고 60초 이하인 영상만 필터링
if not is_live and duration_seconds <= 60:
filtered_videos.append(video)
#필터링된 영상을 카테고리별로 분류
return categorize_videos(filtered_videos)카테고리 분류 함수 시작부분
def categorize_videos(videos):
category_keywords = {
'게임': '게임 게임실황 게임리뷰 게임공략 게임추천 ...',
'요리': 'cook 레시피 음식 맛집 쿠킹 먹방 주방 ...',
'음악': 'music kpop 노래 뮤직 클래식 힙합 재즈 춤 playlist ...',
...
}
category_weights = {
'게임': 1.3,
'요리': 1.2,
'음악': 1.3,
'교육': 1.0,
'여행': 1.2,
'뷰티': 1.2,
'테크': 1.1,
'스포츠': 1.2,
'일상': 1.2,
'영화': 1.1,
'동물': 1.1,
'키즈': 1.0,
'뉴스': 1.2,
'춤': 1.3,
'예능': 1.2,
}
#TF-IDF 벡터화 설정: 한글, 영어 단어 추출 / 1그램, 2그램 사용
vectorizer = TfidfVectorizer(
stop_words=None, #불용어 제거 x
token_pattern=r'[A-Za-z가-힣]+',
ngram_range=(1, 2),
min_df=2, #최소 2개 문서에서 등장 단어만 사용
max_df=0.9 #90% 이상 문서에서 등장 단어 제외
)키워드 지정을 많이 해놓은 상황이라 그대로 넣으면 너무 길어져 일부는 생략함
영상과 카테고리 간 유사도 계산
video_texts = [f"{v['title']} {v['description']}" for v in videos] #영상 제목과 설명을 하나로 결합
category_texts = list(category_keywords.values())
all_texts = video_texts + category_texts #영상 텍스트와 카테고리 텍스트 결합
tfidf_matrix = vectorizer.fit_transform(all_texts) #TF-IDF 벡터화 수행
#영상 벡터와 카테고리 벡터 분리
video_vectors = tfidf_matrix[:len(videos)]
category_vectors = tfidf_matrix[len(videos):]
#영상이랑 각 카테고리 간의 유사도 계산
similarities = cosine_similarity(video_vectors, category_vectors)
categories = list(category_keywords.keys())카테고리를 분류하고, 카테고리와 유사도 점수를 기준으로 영상을 정렬
all_categorized_videos = []
# 각 영상에 대해 유사도 계산 후 가장 적합한 카테고리 선정
for i, video in enumerate(videos):
category_scores = similarities[i] # 영상과 각 카테고리 간의 유사도
weighted_scores = [score * category_weights[cat] for score, cat in zip(category_scores, categories)] # 가중치 반영한 유사도 계산
best_score = np.max(weighted_scores) #가장 높은 유사도 점수
best_category_idx = np.argmax(weighted_scores) #가장 적당한 카테고리 인덱스
category = categories[best_category_idx] #적합한 카테고리 이름
if best_score < 0.05: #유사도가 기준 이하인 경우 제외
continue
#영상 정보,카테고리 정보 저장
video_info = {
'title': video['title'],
'description': video['description'],
'video_id': video['video_id'],
'published_at': video['published_at'],
'similarity_score': float(best_score),
'category': category,
'created_at': datetime.now()
}
all_categorized_videos.append(video_info)
#유사도 점수 기준 내림차순 정렬
all_categorized_videos.sort(key=lambda x: x['similarity_score'], reverse=True)
return all_categorized_videos필터링 과정을 거친 후 DB에 저장
def store_videos_in_mongo(videos, db):
if db is not None: #DB 연결 확인
collection = db['recommend'] #'recommend' 컬렉션 선택
for video in videos:
if collection.find_one({"video_id": video['video_id']}) is None: #중복 확인
try:
collection.insert_one(video) #영상 데이터 삽입
print(f"저장된 영상 ID: {video['video_id']}") #저장된 영상 ID 출력
except Exception as e:
print(f"MongoDB 저장 중 오류: {str(e)}")
else:
print(f"이미 저장된 영상 ID: {video['video_id']}")
else:
print("MongoDB 연결 실패")
def main():
db = connect_mongodb()
videos = get_videos(max_results=1000) #최대 1000개 비디오 가져오기
print(f"가져온 비디오 수: {len(videos)}") #가져온 비디오 수 출력
categorized_videos = filter_and_categorize_videos(videos) #비디오 필터링 / 카테고리 분류
store_videos_in_mongo(categorized_videos, db) #분류된 비디오를 DB에 저장
if __name__ == "__main__":
main() # main 실행
'개발 > 프로젝트' 카테고리의 다른 글
| 유튜브 웹 페이지 실습 (2) | 2024.09.09 |
|---|---|
| [React] 영화 서비스 (0) | 2024.08.20 |
| [React] 로그인 페이지 구현 (0) | 2024.08.13 |
| [JS] 단어 추측 (0) | 2024.08.12 |
| [JS] 가위바위보 (vs PC) (0) | 2024.08.09 |



